Chapitre 4 : Chaînes de caractères⚓︎
Partie A - Représentation d'un texte en machine⚓︎
Pour stocker un texte dans la mémoire d'un ordinateur, pour transmettre un texte à une imprimante, pour envoyer un email, etc., il est nécessaire de pouvoir encoder ce texte sous forme de bits, en associant à chaque caractère du texte une séquence de bits.
Plusieurs difficultés apparaissent. Il faut que les différentes machines qui doivent manipuler le texte utilisent le même encodage. Cet encodage doit permettre de représenter le plus grand nombre de caractères différents possible, dont un certain nombre de caractères non imprimables qui permettent de signaler le début et la fin du texte, une nouvelle ligne, une tabulation, etc.. Enfin, il faut prendre garde que l'encodage ne nécessite pas un trop grand nombre de bits pour chaque caractère, faute de quoi le stockage en mémoire pourrait être peu optimal.
Encodage ASCII⚓︎
Dans les années 60 est apparue la norme ASCII (American Standard Code for Information Interchange ou code américain normalisé pour l'échange d'information) qui permet d'encoder 128 caractères sur 7 bits chacun :
- 34 caractères non imprimables (dont l'espace), codés de
0à32et127, - 10 chiffres indo-arabes, codés de
48à57, - 26 lettres latines majuscules, codées de
65à90, - 26 lettres latines minuscules, codées de
97à122, - 32 autres signes (ponctuation, symboles mathématiques, etc.), codés de
33à47, de58à64, de91à96et de123à126.
Si n est un entier compris entre 33 et 126, alors l'expression chr(n) correspond au caractère associé à n dans l'encodage ASCII.
Si c est un caractère ASCII, alors l'expression ord(c) correspond à l'entier associé au caractère c.
Exercice 4-01 : Utilisation des fonctions chr et ord
Carnet Jupyter à télécharger ici
Carnet Jupyter accessible sur CAPYTALE
Voici la table ASCII complète :
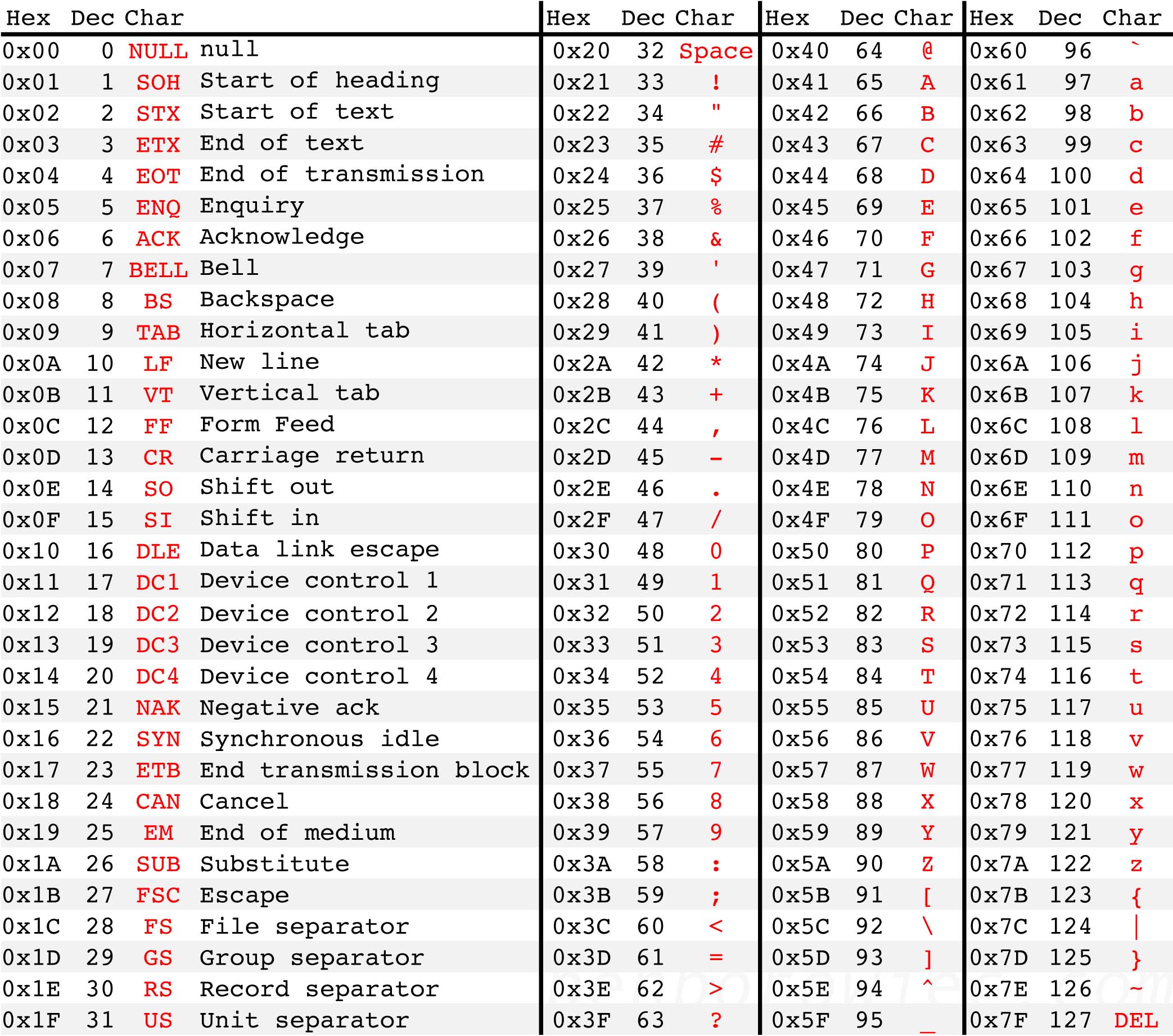
La norme ASCII permet d'écrire du texte en anglais, mais pas dans la très grande majorité des autres langues puisque seuls les caractères latins non accentués sont disponibles.
Encodages ISO 8859⚓︎
L'Organisation Internationale de Normalisation (ISO) a proposé seize extensions de la norme ASCII permettant de représenter 256 caractères sur 8 bits chacun : c'est la norme ISO 8859.
Les 128 premiers caractères sont les mêmes que la norme ASCII. Les 128 derniers caractères dépendent de l'extension utilisée. En particulier, l'encodage latin-1 (ISO 8859-1) permet d'écrire la plupart des langues d'Europe occidentale dont le français. D'autres encodages permettent d'écrire l'alphabet cyrillique (ISO 8859-5), arabe (ISO 8859-6), grec (ISO 8859-7), hébreu (ISO 8859-8), turc (ISO 8859-9).
Si n est un entier compris entre 161 et 255, alors l'expression chr(n) correspond au caractère associé à n dans l'encodage latin-1.
Si c est un caractère latin-1, alors l'expression ord(c) correspond à l'entier associé au caractère c.
Exercice 4-02 : Encodage latin-1
Carnet Jupyter à télécharger ici
Carnet Jupyter accessible sur CAPYTALE
Encodage Unicode (UTF-8)⚓︎
L'encodage ISO 8859 permet d'écrire des textes dans plusieurs langues, mais pas d'écrire un texte composé d'un mélange de caractères de plusieurs langues. C'est pourquoi l'ISO a mis au point un jeu de caractères universel (Universal Character Set) comprenant actuellement plus de 130 000 caractères codés sur 21 bits, et qui pourrait théoriquement en accueillir plus de quatre millions codés sur 32 bits. Les 256 premiers de ces caractères sont les mêmes que ceux de la norme latin-1.
Cependant, l'utilisation de trois à quatre octets pour coder chaque caractère est très peu optimale puisque les caractères latins accentués sont tous codés entre 0 et 255 (1 octet) et les autres caractères les plus utilisés dans le monde sont codés entre 0 et 65 535 (2 octets).
La norme Unicode a été mise au point pour remédier à ce problème. L'encodage UTF-8 (Universal Transformation Format 8 bits) permet ainsi que chaque caractère soit codé sur le moins d'octets possible, entre 1 et 4.
Par défaut, Python encode les chaînes de caractères en UTF-8.
Les fonctions chr et ord vues précédemment permettent en réalité d'associer un caractère et un code dans l'encodage UTF-8.
Exercice 4-03 : Codes Unicode
Carnet Jupyter à télécharger ici
Carnet Jupyter accessible sur CAPYTALE
Partie B - Opérations sur les chaînes de caractères⚓︎
Une chaîne de caractères vide se note '' ou "".
La fonction len renvoie la longueur de la chaîne, c'est-à-dire son nombre de caractères.
Le caractère numéro k de chaine s'obtient via l'expression chaine[k], sachant que les caractères sont numérotés à partir de 0.
Les expressions chaine.upper() et chaine.lower() renvoie la chaîne en majuscules et en minuscules respectivement.
La concaténation de deux chaînes consiste à les mettre bout à bout, en utilisant l'opérateur +.
L'opérateur * permet de concaténer une chaîne à elle même plusieurs fois de suite.
Activité 4-04 : Opérations sur les chaînes de caractères
Carnet Jupyter à télécharger ici
Carnet Jupyter accessible sur CAPYTALE
Exercice 4-05 : Chiffrement de César
Carnet Jupyter à télécharger ici
Carnet Jupyter accessible sur CAPYTALE
Partie C - Lecture et écriture dans un fichier⚓︎
Activité 4-06 : Lecture et écriture dans un fichier
Carnet Jupyter à télécharger ici
Exercice 4-07 : Conversion d'encodage
Carnet Jupyter à télécharger ici
Partie D - Exercices et activités⚓︎
Exercices 4-08 à 4-12
Activités 4-13 à 4-16
Ce qu'il faut savoir et savoir faire⚓︎
- Connaître quelques caractéristiques des encodages ASCII, ISO 8859 et Unicode.
- Parcourir les caractères d'une chaîne avec une boucle du type
for lettre in chaine:. - Concaténer plusieurs chaînes de caractères.
- Écrire une chaîne de caractères formatée (f-string).
- Ouvrir un fichier en lecture ou en écriture, en précisant l'encodage approprié.
- Lire le contenu d'un fichier texte, en intégralité ou ligne par ligne.
- Écrire dans un fichier texte, en écrasant ou non le contenu préexistant.
- Modifier la norme d'encodage un fichier texte.
- Utiliser les fonctions
chretord. - Déterminer le nombre de caractères d'une chaîne avec la fonction
len. - Accéder au
kème caractère d'une chaîne avec l'expressionchaine[k]. - Utiliser les instructions
upper()etlower()pour mettre tous les caractères d'une chaîne en majuscule ou minuscule.