Cours de NSI Première
Constructions élémentaires Booléens Fonctions Chaînes de caractères Tableaux p-uplets et dictionnaires Tables de données Flottants Algorithmes classiques Index ÉnoncésCours de NSI Première
Constructions élémentaires Booléens Fonctions Chaînes de caractères Tableaux p-uplets et dictionnaires Tables de données Flottants Algorithmes classiques Index ÉnoncésReprésentation d'un texte en machine, exemples d'encodages, opérations sur les chaînes, conversion d'un fichier texte
Pour stocker un texte dans la mémoire d'un ordinateur, pour transmettre un texte à une imprimante, pour envoyer un email, etc., il est nécessaire de pouvoir encoder ce texte sous forme de bits, en associant à chaque caractère du texte une séquence de bits.
Plusieurs difficultés apparaissent. Il faut que les différentes machines qui doivent manipuler le texte utilisent le même encodage. Cet encodage doit permettre de représenter le plus grand nombre de caractères différents possible, dont un certain nombre de caractères non imprimables qui permettent de signaler le début et la fin du texte, une nouvelle ligne, une tabulation, etc.. Enfin, il faut prendre garde que l'encodage ne nécessite pas un trop grand nombre de bits pour chaque caractère, faute de quoi le stockage en mémoire pourrait être peu optimal.
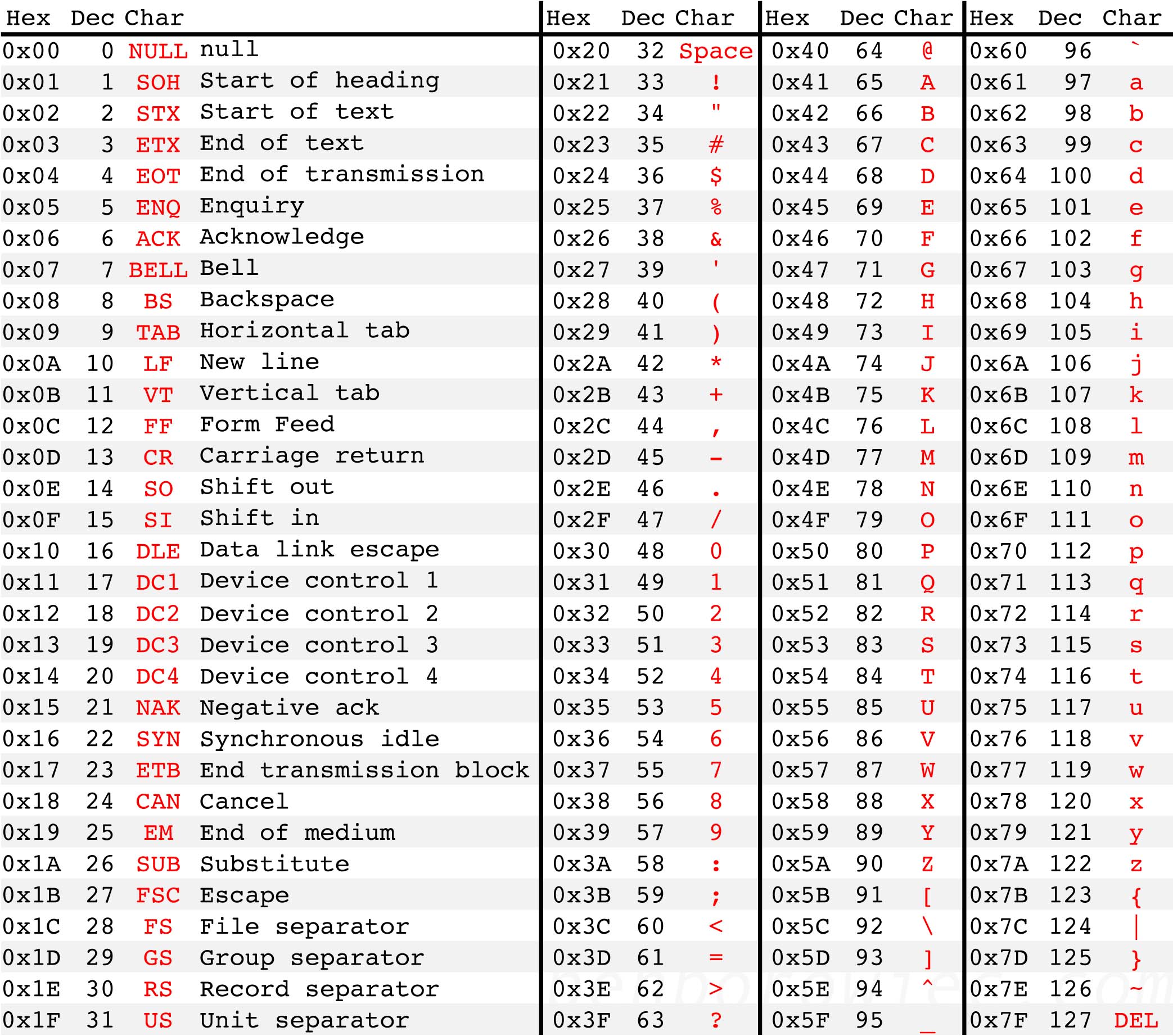
Dans les années 60 est apparue la norme ASCII (American Standard Code for Information Interchange ou code américain normalisé pour l'échange d'information) qui permet d'encoder 128 caractères sur 7 bits chacun :
0 à 32 et 127,48 à 57,65 à 90,97 à 122,33 à 47, de 58 à 64, de 91 à 96 et de 123 à 126.Si n est un entier compris entre 33 et 126, alors la commande Python chr(n) permet d'obtenir le caractère correspondant dans l'encodage ASCII.
Si c est un caractère ASCII, alors la commande ord(c) permet d'obtenir l'entier correspondant au caractère c.
print(chr(33)) # le nombre 33 est écrit sous forme décimale
print(chr(0b00100010)) # le nombre 34 est écrit sous forme binaire
print(chr(0x23)) # le nombre 35 est écrit sous forme héxadécimale
print(ord('$'))
(1) Afficher le code de toutes les lettres majuscules sous la forme A --> 65.
for code in range(65, 91):
print(chr(code), '-->', code, end = ' ')
'\t' (code 9) représente la tabulation horizontale,
le caractère '\n' (code 10) représente le passage à la ligne
et le caractère '\r' (code 13) représente le retour chariot
(retour au début de la ligne sans passage à la ligne).
(2) Définir une fonction texte_vers_code prenant en paramètre d'entrée une chaîne de caractères composée de caractères ASCII et affichant le code de chaque caractère de la chaîne. Penser à écrire la spécification de la fonction.
Remarque : Pour parcourir la chaîne de caractères, on pourra utiliser une boucle pour avec une syntaxe du type : for lettre in chaine:.
def texte_vers_code(chaine):
"""
Affiche le code de chaque caractère composant une chaîne de caractères
- Entrée : chaine (chaîne de caractères)
- Effet de bord : affichage à l'écran
"""
if type(chaine) != str:
raise TypeError('l\'argument doit être une chaîne de caractères')
for lettre in chaine:
print(ord(lettre), end = ' ')
texte_vers_code('bonjour tout le monde !')
La norme ASCII permet d'écrire du texte en anglais, mais pas dans la très grande majorité des autres langues puisque seuls les caractères latins non accentués sont disponibles.
L'Organisation Internationale de Normalisation (ISO) a proposé seize extensions de la norme ASCII permettant de représenter 256 caractères sur 8 bits chacun : c'est la norme ISO 8859.
Les 128 premiers caractères sont les mêmes que la norme ASCII. Les 128 derniers caractères dépendent l'extension utilisée. En particulier, l'encodage latin-1 (ISO 8859-1) permet d'écrire la plupart des langues d'Europe occidentale dont le français. D'autres encodages permettent d'écrire l'alphabet cyrillique (ISO 8859-5), arabe (ISO 8859-6), grec (ISO 8859-7), hébreu (ISO 8859-8), turc (ISO 8859-9).
Si n est un entier compris entre 161 et 255, alors la commande Python chr(n) permet d'obtenir le caractère correspondant dans l'encodage latin-1.
Si c est un caractère latin-1, alors la commande ord(c) permet d'obtenir l'entier correspondant au caractère c.
(3) Afficher sur une ligne tous les caractères dont le code latin-1 est compris entre 223 et 255.
for n in range(223, 256):
print(chr(n), end = ' ')
(4) Après avoir exécuté la cellule suivante, constater que la fonction texte_vers_code définie précédemment est compatible avec un texte encodé en latin-1, et repérer le code des deux caractères accentués de la phrase.
# Première phrase du roman Le Rouge et le Noir de Stendhal
rouge_noir = "La petite ville de Verrières peut passer pour l'une des plus jolies de la Franche-Comté."
texte_vers_code(rouge_noir)
è (code 232) et é (code 233).
L'encodage ISO 8859 permet d'écrire des textes dans plusieurs langues, mais pas d'écrire un texte composé d'un mélange de caractères de plusieurs langues. C'est pourquoi l'ISO a mis au point un jeu de caractères universel (Universal Character Set) comprenant actuellement plus de 130 000 caractères codés sur 21 bits, et qui pourrait théoriquement en accueillir plus de quatre millions codés sur 32 bits. Les 256 premiers de ces caractères sont les mêmes que ceux de la norme latin-1.
Cependant, l'utilisation de trois à quatre octets pour coder chaque caractère est très peu optimale puisque les caractères latins accentués sont tous codés entre 0 et 255 (1 octet) et les autres caractères les plus utilisés dans le monde sont codés entre 0 et 65 535 (2 octets).
La norme Unicode a été mise au point pour remédier à ce problème. L'encodage UTF-8 (Universal Transformation Format 8 bits) permet ainsi que chaque caractère soit codé sur le moins d'octets possible, entre 1 et 4.
Par défaut, Python encode les chaînes de caractères en UTF-8.
Les fonctions chr et ord vues précédemment permettent en réalité d'associer un caractère et un code dans l'encodage UTF-8.
Une chaîne de caractères vide se note '' ou "".
La fonction len renvoie la longueur de la chaîne, c'est-à-dire son nombre de caractères.
len(rouge_noir)
Le caractère numéro n de chaine s'obtient via l'expression chaine[n], sachant que les caractères sont numérotés à partir de 0.
print(rouge_noir[0])
print(rouge_noir[21])
print(rouge_noir[88]) # Il n'y a pas de caractère numéro 88 dans la chaine rouge_noir !
rouge_noir contient 88 caractères numérotés de 0 à 87, ce qui explique l'erreur d'index (IndexError) obtenue en essayant d'afficher le 89ème caractère rouge_noir[88].
Les caractères de chaine situés entre la position numéro n1 (incluse) et la position numéro n2 (non incluse) s'obtiennent via l'expression chaine[n1:n2].
print(rouge_noir[10:21])
Les commandes chaine.upper() et chaine.lower() permettent respectivement de mettre tous les caractères de chaine en majuscule ou minuscule.
print(rouge_noir.upper())
print(rouge_noir.lower())
La concaténation de deux chaînes consiste à les mettre bout à bout, en utilisant l'opérateur +.
print(rouge_noir + ' Ceci est la première phrase du roman Le Rouge et le Noir de Stendhal.')
L'opérateur * permet de concaténer une même chaîne à elle même plusieurs fois de suite.
print(rouge_noir * 5)
(5) Définir une fonction chiffrement prenant en paramètre d'entrée une chaîne de caractères et retournant la chaîne obtenue en remplaçant chaque caractère par celui qui est 4 positions plus loin dans la table Unicode. Les espaces de la chaîne de départ doivent par contre rester des espaces.
Par exemple, la chaîne 'Test' doit être transformée en 'Xiwx'.
def chiffrement(chaine_non_chiffree):
"""
Renvoie une chaîne de caractères modifiée dans laquelle le code de chaque lettre a été augmenté de 4
- Entrée : chaine_non_chiffree (chaîne de caractères)
- Sortie : chaine_chiffree (chaîne de caractères)
"""
if type(chaine_non_chiffree) != str:
raise TypeError('l\'argument doit être une chaîne de caractères')
chaine_chiffree = ''
for lettre in chaine_non_chiffree:
if lettre != ' ':
chaine_chiffree = chaine_chiffree + chr(ord(lettre) + 4)
else:
chaine_chiffree = chaine_chiffree + ' '
return chaine_chiffree
print(chiffrement('Test de chiffrement'))
(6) Définir une fonction dechiffrement permettant de réaliser l'opération réciproque de la fonction chiffrement.
def dechiffrement(chaine_chiffree):
"""
Renvoie une chaîne de caractères modifiée dans laquelle le code de chaque lettre a été diminué de 4
- Entrée : chaine_chiffree (chaîne de caractères)
- Sortie : chaine_non_chiffree (chaîne de caractères)
"""
if type(chaine_chiffree) != str:
raise TypeError('l\'argument doit être une chaîne de caractères')
chaine_non_chiffree = ''
for lettre in chaine_chiffree:
if lettre != ' ':
chaine_non_chiffree = chaine_non_chiffree + chr(ord(lettre) - 4)
else:
chaine_non_chiffree = chaine_non_chiffree + ' '
return chaine_non_chiffree
print(dechiffrement('Xiwx hi híglmjjviqirx'))
(7) Définir une fonction compte_lettre prenant deux paramètres d'entrée (une chaîne de caractères et une lettre) et retournant le nombre de fois que cette lettre apparaît dans la chaîne.
def compte_lettre(chaine, lettre):
"""
Compte le nombre de fois où une lettre particulière apparaît dans une chaîne de caractères
- Entrée : chaine (chaîne de caractères), lettre (caractère)
- Sortie : compteur (entier de caractères)
"""
if type(chaine) != str or type(lettre) != str:
raise TypeError('les arguments doivent être des chaînes de caractères')
if len(lettre) != 1:
raise ValueError('le second argument doit être une chaîne de longueur 1')
compteur = 0
for car in chaine:
if car.upper() == lettre.upper():
compteur = compteur + 1
return compteur
phrase = 'Portez ce vieux whisky au juge blond qui fume.'
for code in range(65, 91):
lettre = chr(code)
cpt = compte_lettre(phrase, lettre)
print(f"La lettre {lettre} apparaît {cpt} fois dans la phrase.")
f"La lettre {lettre} apparaît {cpt} fois dans la phrase." permet d'intégrer la valeur des variables lettre et cpt à l'intérieur d'une chaîne de caractères. Cette écriture "à trous" pour une chaîne de caractères s'appelle une f-string. On obtiendrait le même affichage en écrivant 'La lettre ' + lettre + ' apparaît ' + str(cpt) + ' fois dans la phrase.'.
(8) Après avoir téléchargé le fichier rougenoir_latin-1.txt depuis le répertoire Téléchargements de la Dropbox du cours de NSI, et placé ce fichier dans le même répertoire que ce Notebook, exécuter la cellule suivante.
with open('rougenoir_latin-1.txt', 'r', encoding = 'latin-1') as fichier:
chapitre1 = fichier.read()
with open(nom_de_fichier, 'r', encoding = un_encodage) as fichier: permet d'ouvrir le fichier nom_de_fichier en lecture ('r' pour read, c'est-à-dire lire).fichier.read() permet de lire l'intégralité du fichier texte et de stocker le contenu sous forme d'une chaîne de caractères.for ligne in fichier:.
La variable chapitre1 contient désormais la chaîne de caractères correspondant au premier chapitre du roman Le Rouge et le Noir, qui a été lu dans le fichier rougenoir_latin-1.txt.
print(chapitre1[0:1000]) ## 1000 premiers caractères de la chaîne
(9) Exécuter les deux cellules suivantes et expliquer l'effet obtenu.
chapitre1 = 'Premier chapitre du roman Le Rouge et le Noir\n\n' + chapitre1
with open('rougenoir_nouveau.txt', 'w', encoding = 'utf-8') as fichier:
fichier.write(chapitre1)
rougenoir_nouveau.txt) le premier chapitre du roman précédé de la ligne "Premier chapitre du roman Le Rouge et le Noir". with open(nom_de_fichier, 'w', encoding = un_encodage) as fichier: permet d'ouvrir le fichier nom_de_fichier en écriture ('w' pour write, c'est-à-dire écrire).'a' (pour append, c'est-à-dire ajouter).
(10) Ecrire une fonction fichier_en_majuscule qui prend en paramètre d'entrée une chaîne nom_de_fichier correspondant à un fichier texte et qui crée un nouveau fichier dans lequel tous les caractères du premier fichier ont été mis en majuscule.
def fichier_en_majuscule(nom_de_fichier):
"""
Met en majuscules le texte contenu dans un fichier
- Entrée : nom_de_fichier (chaîne de caractères)
- Effet de bord : écriture dans un autre fichier
"""
if type(nom_de_fichier) != str:
raise TypeError('l\'argument doit être une chaîne de caractères')
with open(nom_de_fichier, 'r', encoding = 'latin-1') as fichier_source:
texte = fichier_source.read()
with open('majuscule_' + nom_de_fichier, 'w', encoding = 'latin-1') as fichier_cible:
fichier_cible.write(texte.upper())
fichier_en_majuscule('rougenoir_latin-1.txt')
(11) Ecrire une procédure conversion_encodages qui prend en paramètres d'entrée trois chaînes de caractères (nom_de_fichier correspondant à un nom de fichier texte, encodage_source correspondant à l'encodage initial du fichier et encodage_cible correspondant à l'encodage souhaité) et qui réécrit le fichier dans l'encodage souhaité.
Par exemple, l'appel conversion_encodages('rougenoir_latin-1.txt', 'latin-1', utf-8') devra convertir le fichier rougenoir_latin-1.txt de la norme latin-1 vers la norme utf-8.
def conversion_encodages(nom_de_fichier, encodage_source, encodage_cible):
"""
Convertir un fichier d'une norme d'encodage à une autre
- Entrées : nom_de_fichier, encodage_source, encodage_cible (chaîne de caractères)
- Effet de bord : réécriture du fichier
"""
if type(nom_de_fichier) != str or type(encodage_source) != str or type(encodage_source) != str:
raise TypeError('les arguments doivent être des chaînes de caractères')
with open(nom_de_fichier, 'r', encoding = encodage_source) as fichier_source:
texte = fichier_source.read()
with open(nom_de_fichier, 'w', encoding = encodage_cible) as fichier_cible:
fichier_cible.write(texte)
# La taille du fichier en latin-1 est de 7078 octets.
conversion_encodages('rougenoir_latin-1.txt', 'latin-1', 'utf-8')
# La taille du fichier en utf-8 est de 7302 octets.
chr et ord.for lettre in chaine:.len.kème caractère d'une chaîne avec l'expression chaine[k].upper() et lower() pour mettre tous les caractères d'une chaîne en majuscule ou minuscule.format() pour insérer la valeur d'une variable dans une chaîne de caractères.Afficher en ligne tous les caractères dont le code Unicode est compris entre 127750 et 127850.
for code in range(127750, 127851):
print(chr(code), end = ' ')
Ecrire une fonction ascii prenant en paramètre d'entrée une chaîne de caractères écrite en français et renvoyant la chaîne correspondante ne contenant que des caractères ASCII en minuscule.
Par exemple, 'Le portugais est parlé à Ponta Delgada (Açores).' devient 'le portugais est parle a ponta delgada (acores).'
def ascii(phrase):
"""
Transforme une chaîne de caractères en enlevant majuscules et accents.
- Entrée : phrase (chaîne de caractères)
- Sortie : nouvelle_phrase (chaîne de caractères)
"""
if type(phrase) != str:
raise TypeError('l\'argument doit être une chaîne de caractères')
nouvelle_phrase = ''
for lettre in phrase:
lettre = lettre.lower()
if lettre in 'àâä':
nouvelle_phrase += 'a'
elif lettre in 'éèêë':
nouvelle_phrase += 'e'
elif lettre in 'îï':
nouvelle_phrase += 'i'
elif lettre in 'ôö':
nouvelle_phrase += 'o'
elif lettre in 'ùûü':
nouvelle_phrase += 'u'
elif lettre == 'ÿ':
nouvelle_phrase += 'y'
elif lettre == 'ç':
nouvelle_phrase += 'c'
elif lettre == 'æ':
nouvelle_phrase += 'ae'
elif lettre == 'œ':
nouvelle_phrase += 'oe'
else:
nouvelle_phrase += lettre
return nouvelle_phrase
ascii('Le portugais est parlé à Ponta Delgada (Açores).')
Après avoir testé plusieurs fois la fonction suivante, écrire sa spécification :
def phrase_contient(phrase, lettre):
"""
Détermine si oui ou non une lettre est présente dans une phrase.
Attention, la fonction est sensible aux majuscules et aux accents.
- Entrées : phrase, lettre (chaînes de caractères)
- Sortie : booléen (True si la lettre est présente dans la phrase, False sinon)
"""
if lettre in phrase:
return True
else:
return False
phrase_contient('bonjour à tous', 'a')
phrase_contient('bonjour à tous', 'n')
phrase_contient('bonjour à tous', 'O')
Ecrire une fonction contient_toutes_les_lettres prenant en paramètre d'entrée une chaîne de caractères et renvoyant True si la chaîne contient toutes les lettres de l'alphabet latin et False sinon. On ne tiendra pas compte du fait que les lettres soient en majuscule ou en minuscule.
def contient_toutes_les_lettres(phrase):
"""
Détermine si oui ou non une phrase contient toutes les lettres de l'alphabet.
- Entrée : phrase (chaîne de caractères)
- Sortie : booléen (True si la phrase contient toutes les lettres, False sinon)
"""
phrase = ascii(phrase) # on élimine les majuscules et les accents éventuels
for lettre in 'abcdefghijklmnopqrstuvwxyz':
if not phrase_contient(phrase, lettre):
return False
return True
contient_toutes_les_lettres('Portez ce vieux whisky au juge blond qui fume.')
contient_toutes_les_lettres('Portez ce verre d\'eau au juge blond qui rêve.')
Ecrire une fonction nb_voyelles prenant en paramètre d'entrée une chaîne de caractères et renvoyant le nombre de voyelles contenues dans la chaîne.
def nb_voyelles(phrase):
"""
Compte le nombre de voyelles présentes dans une phrase.
- Entrée : phrase (chaîne de caractères)
- Sortie : cpt (entier)
"""
cpt = 0
for lettre in phrase:
if lettre.lower() in 'aàâäeéèêëiîïoôöuùûüyÿ':
cpt = cpt + 1
return cpt
nb_voyelles('Cette phrase contient 11 voyelles.')
nb_voyelles('Il y a quinze voyelles dans cette phrase.')
Après avoir exécuté la cellule suivante, ouvrir le fichier ma_page.html :
mon_texte = "Test d'écriture dans un fichier html"
code_html = """<!DOCTYPE html>
<html>
<head>
<meta charset = 'utf-8'>
</head>
<body>""" + mon_texte + """
</body>
</html>"""
with open('ma_page.html', 'w', encoding = 'utf-8') as fichier:
fichier.write(code_html)
Le texte complet du roman Le Rouge et le Noir est enregistré dans le fichier rouge_noir_complet.txt téléchargeable depuis le répertoire Téléchargements de la Dropbox du cours de NSI.
Ecrire les lignes de code permettant de créer une page HTML contenant l'intégralité du roman Le Rouge et le Noir.
with open('rouge_noir_complet.txt', 'r', encoding = 'utf-8') as fichier:
mon_texte = fichier.read()
code_html = """<!DOCTYPE html>
<html>
<head>
<meta charset = 'utf-8'>
</head>
<body>""" + mon_texte + """
</body>
</html>"""
with open('ma_page.html', 'w', encoding = 'utf-8') as fichier:
fichier.write(code_html)
Améliorer le code de sorte que les passages à la ligne soient visibles et que les numéros de chapitre soient mis en évidence.
mon_texte = ""
with open('rouge_noir_complet.txt', 'r', encoding = 'utf-8') as fichier:
for ligne in fichier:
if 2 <= len(ligne) <= 8:
mon_texte = mon_texte + "<h1>Chapitre " + ligne + "</h1>"
else:
mon_texte = mon_texte + ligne + "<br>"
code_html = """<!DOCTYPE html>
<html>
<head>
<meta charset = 'utf-8'>
</head>
<body>""" + mon_texte + """
</body>
</html>"""
with open('ma_page.html', 'w', encoding = 'utf-8') as fichier:
fichier.write(code_html)
Cent mille milliards de poèmes est un livre de poésie publié en 1961 par Raymond Queneau et qui contient dix sonnets, c'est-à-dire dix poèmes de quatorze vers chacun. Voici les deux premiers sonnets :
Le roi de la pampa retourne sa chemise |
Le cheval Parthénon s'énerve sur la frise |
Les 100 000 000 000 000 poèmes s'obtiennent en choisissant au hasard le premier vers d'un des dix sonnets, puis en choissant au hasard le deuxième vers d'un des dix sonnets, etc.
En se basant uniquement sur les deux sonnets écrits ci-dessus, il est déjà possible de créer 16 384 poèmes différents.
Ecrire une fonction poeme_aleatoire renvoyant un sonnet composé à partir de vers de l'un ou l'autre des deux premiers sonnets de Queneau.
Remarque : les deux premiers sonnets sont contenus dans le fichier poemes_queneau_2.txt téléchargeable depuis le répertoire Téléchargements de la Dropbox du cours de NSI. Les vers sont disposés dans le fichier de la façon suivante :
Aide : pour lire une seule ligne d'un fichier texte, utiliser une instruction du type ligne = fichier.readline().
from random import randint
def poeme_aleatoire():
with open('poemes_queneau_2.txt','r', encoding = 'utf-8') as fichier:
poeme = ''
for k in range(14):
nb_alea = randint(0, 1)
for n in range(2):
ligne = fichier.readline()
if n == nb_alea:
poeme = poeme + ligne
if k == 3 or k == 7 or k == 10:
poeme = poeme + '\n'
return poeme
print(poeme_aleatoire())
Ecrire une fonction poeme_aleatoire_2 renvoyant un sonnet composé à partir de vers de l'un des quatre premiers sonnets de Queneau.
Remarque : les quatre premiers sonnets sont contenus dans le fichier poemes_queneau_4.txt téléchargeable depuis le répertoire Téléchargements de la Dropbox du cours de NSI. Les vers sont disposés de la même façon que précédemment.
def poeme_aleatoire_2():
with open('poemes_queneau_4.txt','r', encoding = 'utf-8') as fichier:
poeme = ''
for k in range(14):
nb_alea = randint(0, 3)
for n in range(4):
ligne = fichier.readline()
if n == nb_alea:
poeme = poeme + ligne
if k == 3 or k == 7 or k == 10:
poeme = poeme + '\n'
return poeme
print(poeme_aleatoire_2())
En exécutant la cellule ci dessous, on importe quatres procédures dans le Notebook.
from directions import *
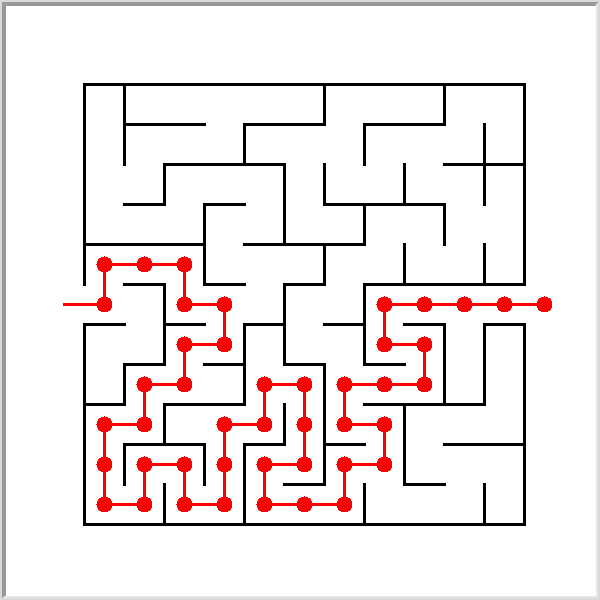
La procédure demarrer_labyrinthe permet d'afficher un labyrinthe à l'écran et de placer la tortue à l'entrée.
demarrer_labyrinthe()
Les procédures haut, bas, gauche et droite permet de déplacer la tortue dans le labyrinthe.
(1) Ecrire dans un fichier mouvements.txt la suite des mouvements que doit réaliser la tortue pour sortir du labyrinthe.
Un pas à droite sera représenté par la lettre D, un pas à gauche par la lettre G, un pas en haut par la lettre H et un pas en bas par la lettre B.
(2) Définir une fonction lire_mouvements prenant en paramètre d'entrée un nom de fichier, lisant le contenu du fichier, et renvoyant la chaîne de caractères composée des lettres D, G, H et B présentes dans le fichier.
def lire_mouvements(nom_de_fichier):
with open(nom_de_fichier, 'r', encoding = 'utf-8') as fichier:
chaine = fichier.read()
return chaine
(3) Définir une procédure deplacer_tortue prenant en paramètre d'entrée une chaîne de caractères composée des lettres D, G, H et B et affichant à l'écran les déplacements successifs de la tortue dans le labyrinthe.
def deplacer_tortue(phrase):
for lettre in phrase:
if lettre == 'H':
haut()
elif lettre == 'B':
bas()
elif lettre == 'G':
gauche()
elif lettre == 'D':
droite()
(4) Utiliser les fonctions précédentes pour afficher l'itinéraire de la tortue de l'entrée à la sortie du labyrinthe.
deplacer_tortue(lire_mouvements('mouvements.txt'))
L'adresse https://raw.githubusercontent.com/PokeAPI/sprites/master/sprites/pokemon/25.png permet d'accéder à une image du Pokemon Pikachu, dont le numéro est 25.

Créer une page HTML contenant l'image de tous les Pokemon dont le numéro est compris entre 1 et 151.
def adresse_image(n):
return f"https://raw.githubusercontent.com/PokeAPI/sprites/master/sprites/pokemon/{n}.png"
code_html = """<!DOCTYPE html>
<html>
<head>
<meta charset = 'utf-8'>
<style type="text/css">
img {margin: 1em; border: 2px solid black;}
</style>
</head>
<body>"""
for num in range(1, 152):
code_html = code_html + f"<img src='{adresse_image(num)}'>"
code_html = code_html + """
</body>
</html>"""
with open('pokemon.html', 'w', encoding = 'utf-8') as fichier:
fichier.write(code_html)